





- 介绍使用PCA来进行特征抽取实现降维。特征选择,是从原始的特征中选出一个特征子集。特征抽取,是通过对现有特征的信息进行推演,构造出一个新的特征子空间。可以理解为特征抽取是尽可能多地保证相关信息的情况下,来实现数据的压缩,特征抽取也可以提高计算效率。
一、什么是主成分分析?
主成分分析(principal component analysis,PCA)是一种广泛应用于无监督线性数据的转换技术,主要应用于降维处理。广泛应用于股票交易市场数据的探索性分析和去燥,以及生物信息学领域的基因组和基因表达水平数据分析等。PCA的目的是从高维数据中找到最大方差的方向,并将数据映射到一个维度不大于原始数据的新的特征子空间上。
假设原始数据的维度为d,通过PCA映射之后产生的子空间维度为k(d >= k)。通过PCA降维,我们可以构建出一个d×k维的转换矩阵W,通过矩阵W将原始数据为d维的数据转换到k维数据上。转换之后,第一主成分的方差是最大的,各个主成分之间是不相关的,通过PCA降维之后,每个主成分之间是正交的。主成分对数据值的范围是高度敏感的,所以通常情况下,我们需要先将特征值进行标准化之后,再使用PCA降维技术。PCA算法由以下6个步骤组成:
1、对数据做标准化处理
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler if __name__ == "__main__": #获取葡萄酒的数据 data = pd.read_csv("G:/dataset/wine.csv") #将数据分为x和y x,y = data.ix[:,1:],data.ix[:,0] #将数据分为训练集和测试集 train_x,test_x,train,y_test_y = train_test_split(x,y,test_size=0.3,random_state=1) #对特征进行标准化处理 std = StandardScaler() train_x_std = std.fit_transform(train_x) test_x_std = std.fit_transform(test_x)2、计算数据的协方差矩阵
通过numpy的cov函数获取数据的协方差矩阵
#获取数据的协方差矩阵 cov_mat = np.cov(train_x_std.T)
3、计算协方差矩阵的特征值和特征向量
通过numpy的linalg.eig函数获取协方差矩阵的特征值和特征向量,通过特征分解,得到一个包含13个特征值的向量和一个13×13维的特征向量。
#获取特征值和特征向量 eigen_vals,eigen_vecs = np.linalg.eig(cov_mat)
4、选择与前k个最大特征值对应的特征向量,其中k为新的特征子空间的维度
通过对特征值进行排序,获取前k个特征值。计算单个方差的贡献和累计方差的贡献,方差贡献率是指单个特征值与所有特征值和的比值。
#获取所有特征值的和 eigen_sum = sum(eigen_vals) #计算单个特征的贡献方差 var_exp = [(i / eigen_sum) for i in sorted(eigen_vals,reverse=True)] #获取累计方差 cum_var_exp = np.cumsum(var_exp) #绘图 plt.bar(range(1,14),var_exp,alpha=0.5,align="center",label="累计方差贡献率") plt.step(range(1,14),cum_var_exp,where="mid",label="单个方差贡献率") plt.ylabel("方差贡献率") plt.xlabel("主成分") plt.legend(loc="best") plt.show()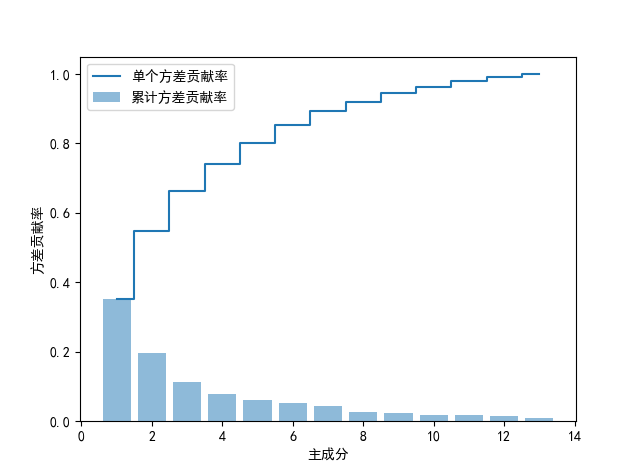
通过上图各个特征值的方差贡献率可以发现,第一主成分和第二主成分占了60%,下面就取k=2,为了方便后面作图。
5、通过前k个特征向量构建转换矩阵W
#获取特征对 eigen_pairs = [(np.abs(eigen_vals[i]),eigen_vecs[:,i]) for i in range(len(eigen_vals))] #对特征对进行排序 eigen_pairs.sort(reverse=True) #获取映射矩阵W W = np.hstack((eigen_pairs[0][1][:,np.newaxis], eigen_pairs[1][1][:,np.newaxis]))
6、将数据维度为k的数据通过转换矩阵W映射到维度为d的空间上
#对训练数据通过映射矩阵W进行转换 train_x_std_pca = train_x_std.dot(W) #绘制散点图 colors = ["r","b","g"] markers = ["s","x","o"] for l,c,m in zip(np.unique(train_y),colors,markers): plt.scatter(train_x_std_pca[train_y==l,0],train_x_std_pca[train_y==l,1],c=c,label=l,marker=m) plt.xlabel("PC1") plt.ylabel("PC2") plt.legend(loc="lower left") plt.show()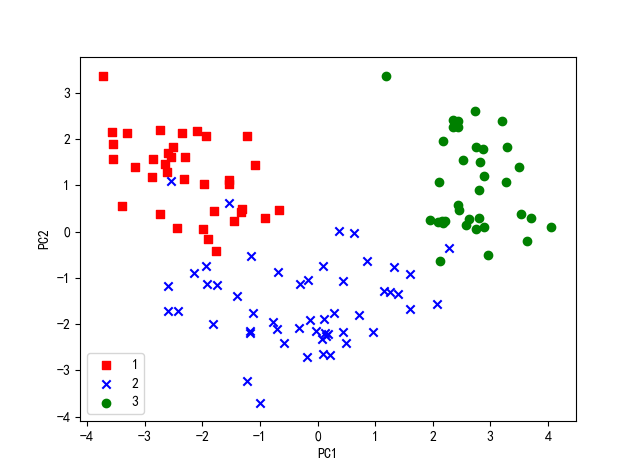
通过观察上图可以发现,PC1相对于PC2而言,数据更多的是沿着PC1方向上分布,通过上图展示后,3类数据通过线性分类器就能够很好的区分。
二、通过sklearn来实现PCA降维
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA if __name__ == "__main__": #获取葡萄酒的数据 data = pd.read_csv("G:/dataset/wine.csv") #将数据分为x和y x,y = data.ix[:,1:],data.ix[:,0] #将数据分为训练集和测试集 train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3,random_state=1) #对特征进行标准化处理 std = StandardScaler() train_x_std = std.fit_transform(train_x) test_x_std = std.fit_transform(test_x) #创建一个PCA模型,并设置降维后的维度为2 pca = PCA(n_components=2) logistic = LogisticRegression() train_x_std_pca = pca.fit_transform(train_x_std) test_x_std_pca = pca.fit_transform(test_x_std) logistic.fit(train_x_std_pca,train_y) print("训练集上的准确率:",logistic.score(train_x_std_pca,train_y)) print("测试集上的准确率:",logistic.score(test_x_std_pca,test_y))训练集上的准确率: 0.967741935484
测试集上的准确率: 0.925925925926
文章标签: 顶: 0踩: 0本文链接:https://www.lezhuanwang.net/kepu/41850.html『转载请注明出处』
相关文章
- 2022-12-03沙发选择什么材质的好(沙发选购主要看这四个方面)
- 2022-12-01怎么建微信群当群主(建立微信群的方法)
- 2022-11-30网店模板制作教程(做电商主图详情页套用模板制作方法)
- 2022-11-30六项精进的内容是什么(六项精进主要内容详解)
- 2022-11-30超级店长有必要买吗(淘宝店铺超级店长的主要功能)
- 2022-11-30企业危机公关是做什么的(危机公关的主要工作和注意事项)